文字コードなんて日頃意識しない。なにそれ? という人が多いのではないでしょうか。
はっきり言って、学生の頃は殆ど意識してませんでした。
でも、SEとして働いていると文字コードは必ず意識します。 文字コードが原因のシステム障害は多々ありますので知っておくと良いでしょう。
文字コードとは
コンピュータで文字を表現するときに、あらかじめ決められたバイト形式で各文字を表現します。
このバイト形式を文字コード、文字と文字コードの対応関係を文字コード体系と言います。
Shift-JISという文字コード体系の場合、全角文字は2バイトで表現されています。
- (例 Shift-JIS)
- あ 130 16
- い 130 18
- う 130 20
- え 130 22
- お 130 24
文字コード体系は複数あって、OSにより使っている文字コード体系が異なります。
- Windows Shift-JIS
- Linux UTF-8 (昔はEUC)
- Mac UTF-8
- HP-UX Shift-JIS
- Solaris EUC
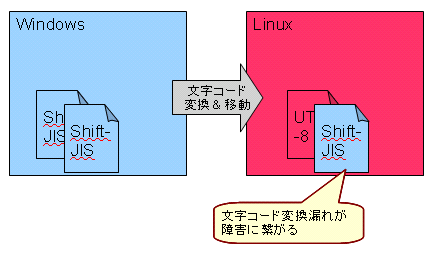
Windowsで書いたテキストファイル(Shift-JIS)をLinuxで開くとUTF-8形式で開こうとするので文字化けが起きてしまいます。

文字コードでの苦労 ヒューマンエラー
先程書いたように、何も考慮しないとWindowsで書いたテキストファイルは Linuxで正しく見られません。
最近のシステム開発だと、WindowsのPCでプログラムやデータを作り、 Linuxのサーバにそれらのファイルを移してシステムを動かします。 各ファイルの文字コードをLinux用に変換せずに、そのまま移すと文字化けが起きてしまい 意図しない動作となってしまいます。
システムをリリースする直前は何度もWindows→Linuxとデータを移します。 1度でも文字コード変換を忘れるとプログラムが動かなくなり大きな障害になってしまいます。
設計時の悩み 1.5倍問題
最近は安価で高品質なLinuxを使ったシステムが増えてきています。 なので、「今までWindowsやSolarisで作っていたシステムを再開発でLinuxに」という動きがあります。
ところが、そのときにこの1.5倍問題が出てきます。
WindowsやSolarisの文字コードであるShift-JISやEUCは、2バイトで日本語文字を表現できます。 対してLinuxのUTF-8は3バイト。 「あいうえお」というデータを格納するために10バイト(5文字×2バイト)で良かったものが 15バイト(5文字×3バイト)となり、UTF-8だと1.5倍の領域が必要になります。
「ほんの少しの差では?」と思うかもしれませんがシステム全体の全角文字を扱う処理の見直し、 DBの格納領域見直し、更には使用するメモリの見直しと再設計する範囲が大きくなってしまいます。
そして、1.5倍を忘れてシステムを再開発するとメモリ不足、容量不足になりシステムが動かないということがあります。